

AWS每隔一段時間總會有些讓人意想不到的怪料出現。有些讓人看了實在不知道要怎麼用(其實是自己學識淺薄,所以搞不清哪裡好用),有些則是讓人忍不住在心裡面喊著:
哇靠,早就在想世界上有沒有這種東西啊!
今天開箱的是AWS Athena。用一句簡單的話來說就是:
把你存在S3上面的格式化文字檔當成資料庫,讓你做SQL查詢
這樣到底什麼好用?
遇到過的就知道什麼好用啦... 比如說我經常被問說:
“請問一下,某個資料夾裡的檔案,在某個區間被多少個IP播放? "
我會在心裡面暗叫一下:
"老大,log可不是資料庫啊,你要我命啊?"
當然事情還是得做,於是在從前,我也許會用grep+awk這樣,然後要多一點額外的處理的話,只好再匯入Excel去方便使用滑鼠亂按。透過Athena的話,就是直接下SQL查詢就好了。
看到AWS的blog裡寫的新聞稿,我忍不住興奮,自己立刻動手,拿以前常用到的Wowza的log來開刀。
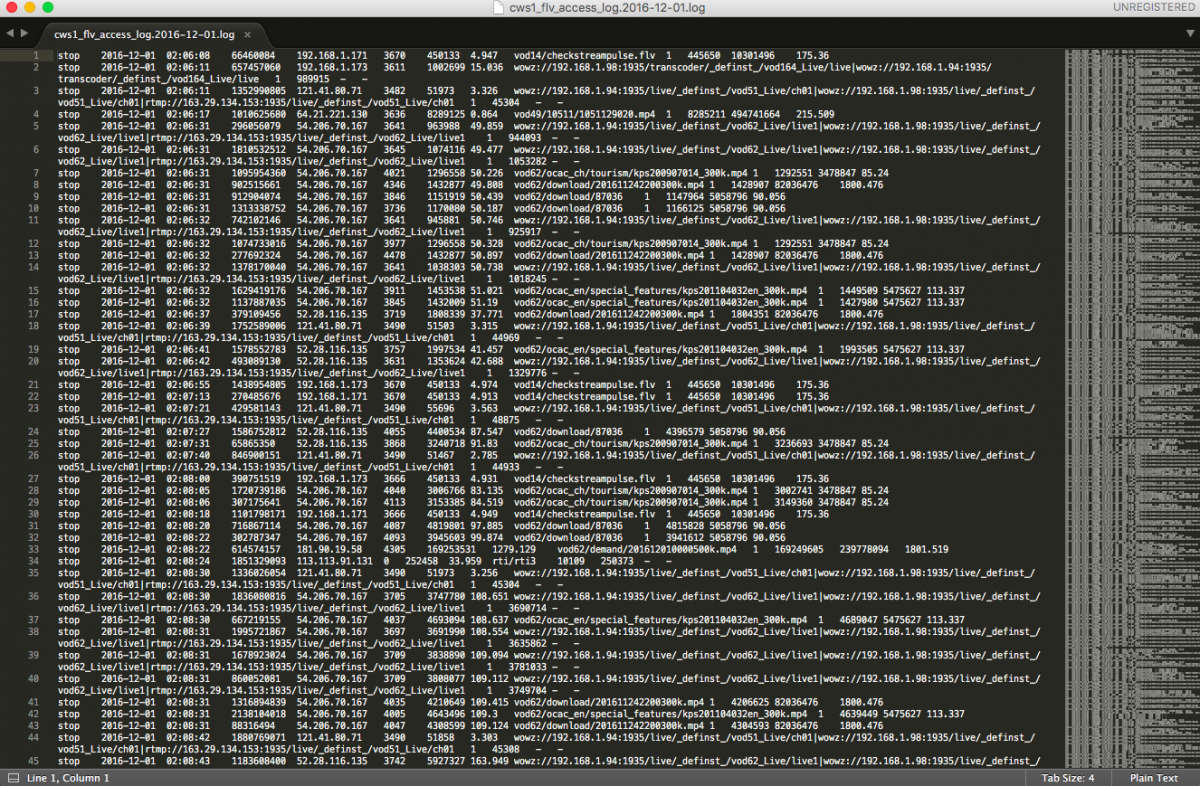
首先打開log,先搞清楚裡面的欄位長相和資料類型(其實看log4j的config就好了,我的log例子有13個欄位)。
再來準備一個S3 bucket,把你要處理的檔案(們)放到其中的一個資料夾裡面。我隨手抓了三個log檔上到一個新建立的bucket裡面。
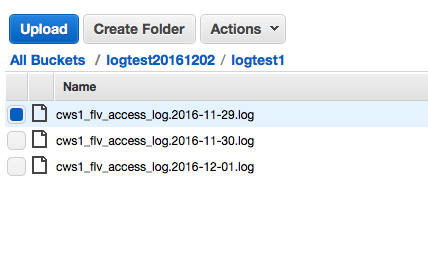
(檔案三個加起來接近15MB)
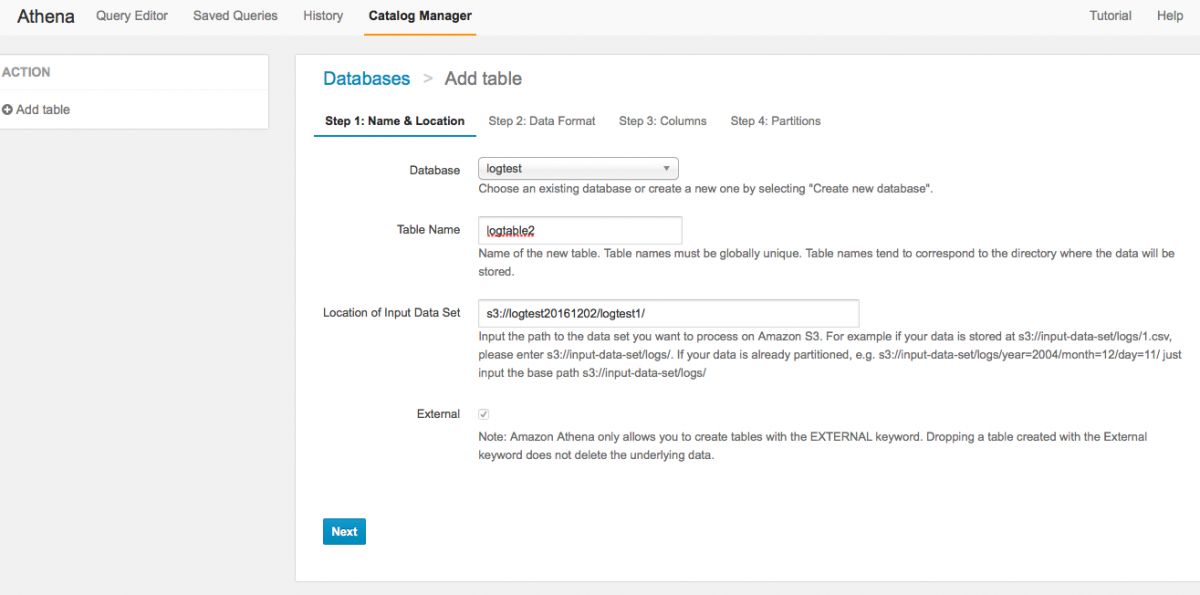
接著進入Athena的頁面,開始建立資料庫。直接選Add table就可以順便建立資料庫了。
要指定來源bucket --- 來源Bucket可以是一整個資料夾! 這意思就是在資料夾底下不管有幾個檔案,Athena會把他們全部混在一起當作同一個資料庫處理 (撒花~~~)。
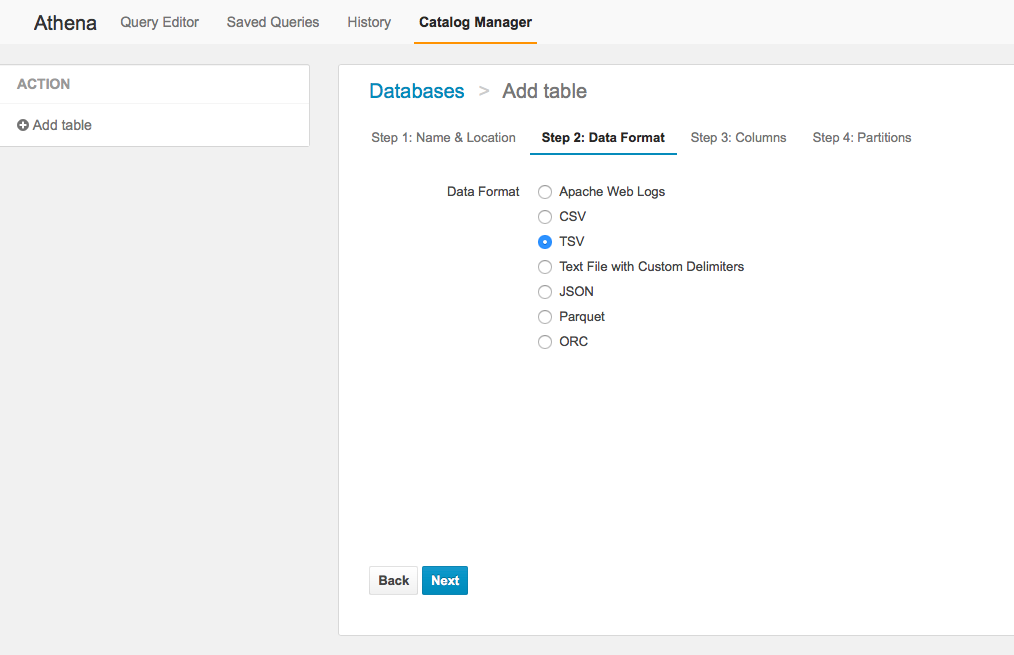
然後選擇資料來源格式 (可惜沒有xls? )。
再來來到唯一麻煩的地方-建立欄位。如果log的欄位落落長,這裡就比較討厭一點了。剛剛從log4j的設定檔看到的欄位名稱就直接拿來套用就是了(別忘了,欄位名稱不可以有橫線,只能有底線喔)。
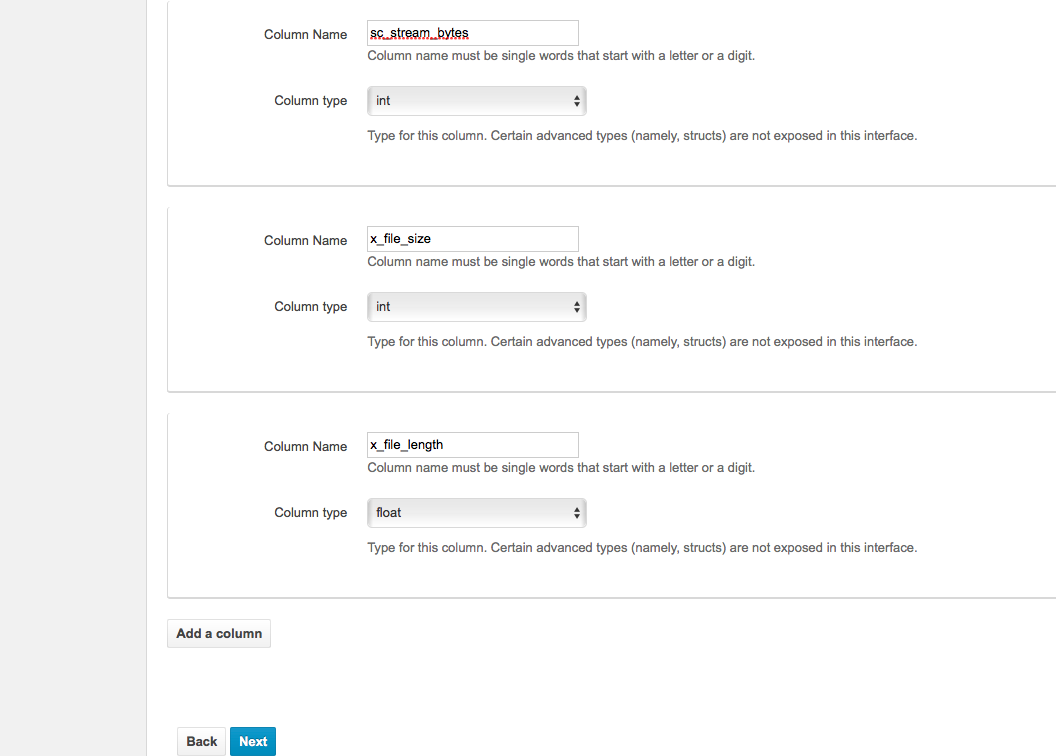
(如果沒有要做加總的話,我想應該全部使用string就好了吧?)
然後? 然後就好了啦! 這次只是開箱,所以什麼Partition到底是幹嘛的根本不知道,隨便按Next過去了。
接著就引導進入了Query Editor畫面了。先試試速度...
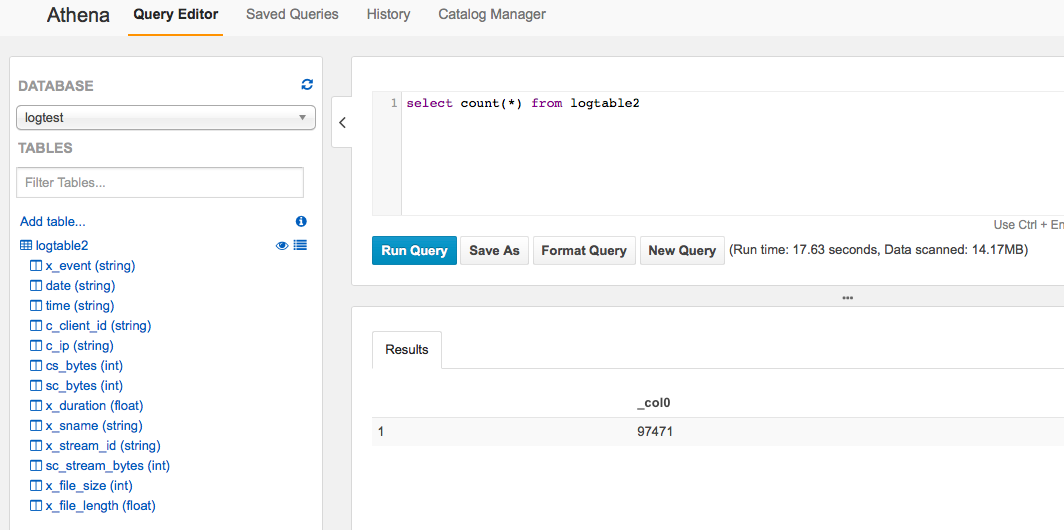
有點慢... 9萬多行需要17秒數完。不過有這東西,省掉以前很多功夫,所以慢一些,我也不那麼在意啦...
再來看看是不是真的能SQL。先用select count看看吧...
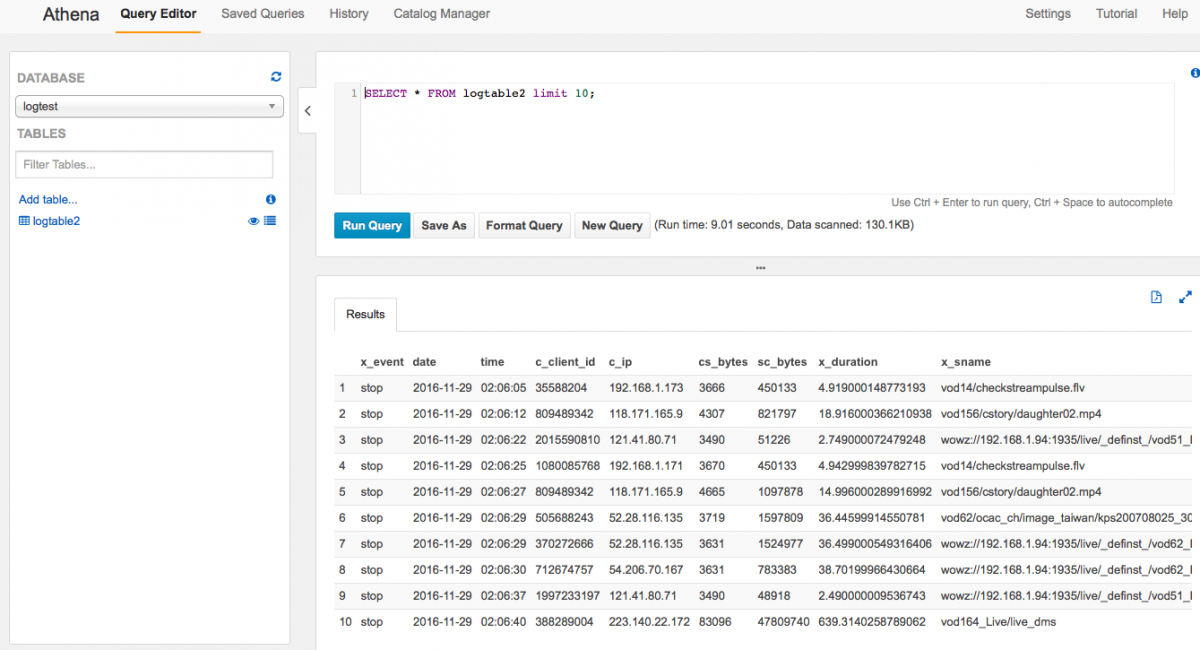
真的可以耶!
那... 試試看別的,來個排序吧?
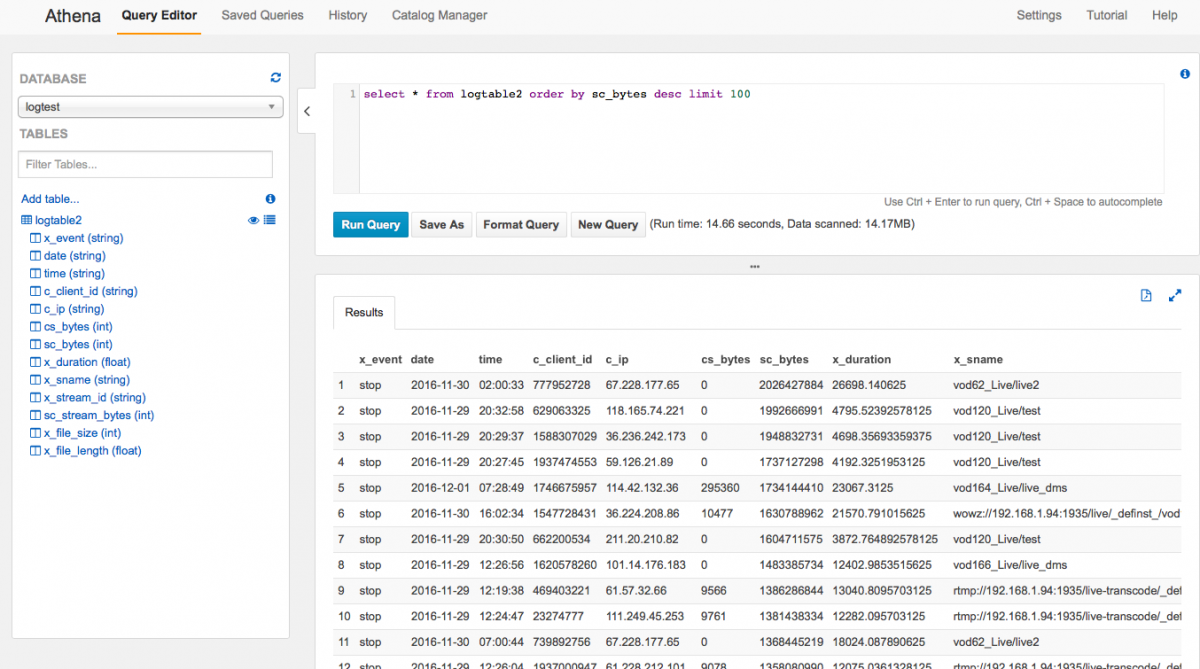
好吧,最後來個我在最前面的問題
“請問一下,某個資料夾裡的檔案,在某個區間被多少個IP播放? "
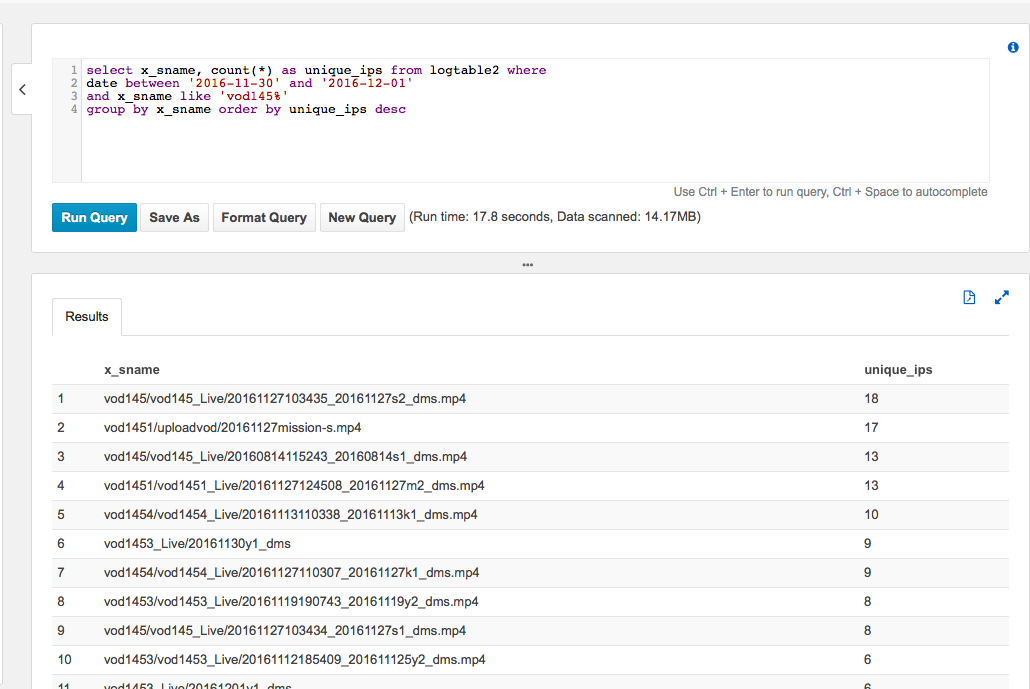
由於我上傳的log是一天一個檔案,所以上面這個例子,是跨過兩個log進行查詢出來的結果。
太棒了啦!

貌似不管查什麼簡單或複雜,花的時間就只有取決於你的文字檔有幾行...
好吧,真的不錯用。按一個特大的讚!
